
Abstract
There are at least 6,000 languages spoken in the world today [1]. The world’s languages are represented by a variety of writing systems called “orthographies.” Orthographies are the symbols used to represent spoken language. You are looking at one type of orthography now, as you read this! So, an orthography consists of the symbols used to turn a spoken language into a written form. However, orthographies differ in the size of the sound unit that is represented by each symbol. For example, in alphabetic orthographies, such as English, Spanish, and Russian, each symbol represents an individual sound called a phoneme (e.g., the/b/sound in “book” is one phoneme). In non-alphabetic orthographies, such as Chinese or Cherokee, the symbol represents a larger sound unit such as a syllable (e.g., such as “pro” in the word “project”). Over 400 orthographies exist today. Each orthography can be classified as alphabetic, such as English, or non-alphabetic, such as Chinese. In this article, we will first learn about the characteristics of different orthographies. Then, we will use these characteristics to help understand how different writing systems affect the process of reading. We will then learn about the brain regions involved in reading.
First, let us talk about alphabetic orthographies. There are several different alphabets that are used to create written languages. For example, English uses the Latin alphabet, and 26 symbols, or letters, to represent the spoken language. Norwegian and Slovak also use the Latin alphabet, or the same set of symbols, but Norwegian includes three vowels not used in English (å, æ, ø) and Slovak uses a series of accent marks to indicate how a letter is spoken (for example, ó or š), resulting in the use of 46 symbols to represent the spoken language. Most European languages, including English, French, Spanish, Italian, Dutch, Norwegian, German, Portuguese, Czech, Slovak, Hungarian, Polish, Danish, Welsh, Swedish, Icelandic, Finnish, and Turkish, use the Latin alphabet [1].
There are other alphabets that use different sets of symbols to represent the spoken language, but still code the language at the level of the phoneme. These alphabets include the Cyrillic alphabet, which is used for the Russian, Bulgarian, and Ukrainian languages; the Devanagari alphabet, which is used for Hindi, one of the official languages of India, the Greek alphabet, which is only used for the Greek language, and the Hangul alphabet, which is used for the Korean language. Some languages, such as Serbo-Croat, use both the Latin and the Cyrillic alphabets. An alphabetic orthography that only contains consonants, and not vowels, is called an “abjad.” Hebrew and Arabic are sometimes classified as abjads, because vowels traditionally are not included when writing. However, today, we often use accent marks to show where a vowel should be, leading many people to classify both Hebrew and Arabic as alphabets, not abjads. In Figure 1, you can compare several different alphabetic (and non-alphabetic) orthographies used to write out the same statement: “I think I can.”
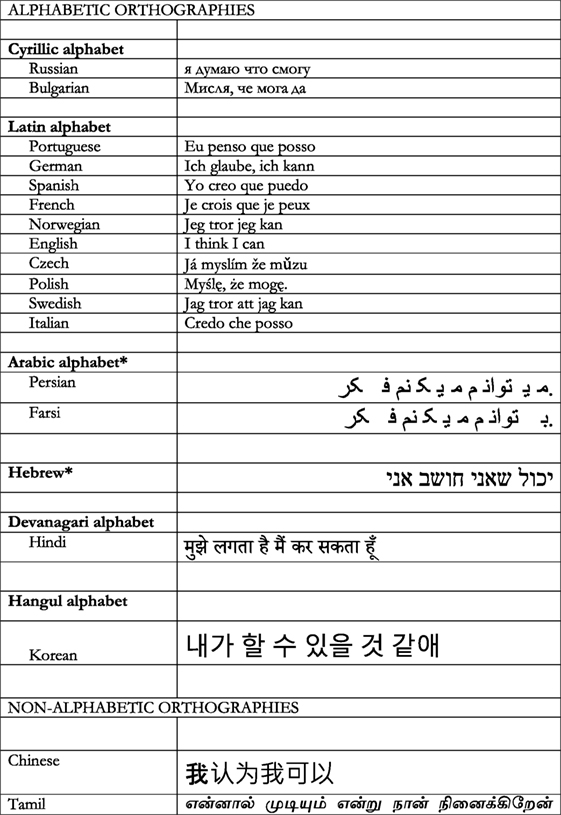
- Figure 1 - Examples of different orthographies coding the English sentence “I think I can.”
- *These languages are read from right to left.
Alphabetic orthographies also differ in how well the phonemes (sounds) and the graphemes (symbols or letters) match up. In some languages, such as Spanish, Italian, and German, almost every letter represents only one sound. When each letter is always pronounced exactly the same way, the mapping is said to be “consistent” and the orthography is called “shallow.” In other languages, such as English and Danish, a letter can have many pronunciations, such as the two different/c/sounds in “circus.” In this case, the mapping is said to be “inconsistent,” and the orthography is called “deep.” Thus, Spanish is a consistent or shallow orthography, and English is an inconsistent or deep orthography. Although not everyone agrees on how to compare the consistencies between letters and sounds across languages, researchers generally agree that Finnish, Greek, Italian, Spanish, German, Serbo-Croat, Turkish, and Korean are relatively shallow or consistent orthographies, while Portuguese, French, and Danish contain more inconsistent mappings between phonemes and graphemes. English is the most inconsistent language in the world!
Now, let us talk about non-alphabetic orthographies. Non-alphabetic orthographies represent either the syllable (for example, Cherokee, Tamil, or Japanese Kana) or a one-syllable unit of meaning (as in Chinese, Japanese Kanji) with each symbol. Similar to the alphabetic orthographies, a unit of spoken language is represented by a symbol, but in the non-alphabetic orthographies, unlike the alphabetic ones, that unit of spoken language is larger than just a phoneme. Chinese is often referred to as a pictograph (a language made up of pictures), because people think that the characters are pictures of the words they represent. In fact, very few Chinese characters are actually pictures of the words they represent. Rather, in Chinese, the symbols represent a unit of pronunciation (a syllable) that is also a unit of meaning (a morpheme), thus Chinese is considered a morpho-syllabic writing system. Approximately 80–90% of Chinese characters also contain what is called a phonetic radical. A phonetic radical is just one part of the character that provides a clue as to how to say the word. You can see examples of Chinese and Tamil in Figure 1.
As we can see, there are some things that are the same about all orthographies, and there are some things that are different between orthographies. All orthographies represent spoken language with written symbols. Yet, the portion of spoken language that is coded and the consistency of the mappings between sounds and symbols differs across orthographies. Next, we will explore how these similarities and differences affect reading skills, and see how the brain reads different languages.
Is Learning to Read Harder in Some Orthographies than Others?
How quickly and how well children learn to read differs across languages. Some of these differences are because of the characteristics of the writing system [2]. One large study compared children learning to read across 14 different alphabetic orthographies and found that, by the end of Grade 1, children learning to read in shallow orthographies, such as Spanish, Finnish, and Greek, made fewer mistakes when reading and read faster than children learning to read in more inconsistent orthographies, such as Danish and English [2]. Some of the differences in learning to read across languages might be because children are taught to read differently in different countries. But, research studies overwhelmingly support the idea that learning to read is easier in consistent orthographies than in inconsistent orthographies. English readers take longer to learn to read than readers in almost all other alphabetic orthographies, and Chinese readers take even longer [3].
Do Children have Different Reading Problems in Different Orthographies?
Children who have great difficulty learning to read may have a learning problem known as developmental dyslexia. Children with dyslexia are not able to read as well as other kids who are the same age. Also, their difficulties with reading are not because of poor teaching, poor sight or hearing, or because of other brain disorders. It is believed that about 5% of children in all languages have severe reading problems.
Children with dyslexia, in any language, have a hard time converting written symbols into the sounds they represent [3]. This skill is called phonological decoding. However, the degree that problems with phonological decoding interferes with reading differs across languages. Children with dyslexia in consistent orthographies, such as German, Spanish and Italian, can read words correctly, showing that they have good phonological decoding skills, but they tend to be very slow readers. In contrast, problems with phonological decoding affect reading greatly in inconsistent orthographies, such as English. Children with dyslexia in English tend to make a lot of mistakes when reading words [3]. Children with dyslexia in Chinese, a non-alphabetic language, also have problems with phonological decoding, which can affect reading. Chinese readers who have problems with phonological decoding might not be able to use the phonetic radicals within a Chinese character as a clue to help with pronouncing that word. However, not being able to use the phonetic radicals in a Chinese character is not the main problem for Chinese children with dyslexia. In Chinese, understanding how the character represents the meaning of the word, a skill called “morphological awareness,” is a more important skill for reading, and children with dyslexia often have problems with this skill [4]. Thus, phonological decoding is important for learning to read in Chinese, but probably less important than for children learning to read in an alphabetic orthography [3]. And within alphabetic orthographies, phonological decoding problems create more reading problems in inconsistent orthographies such as English than in consistent orthographies such as Spanish.
We see similarities and differences in reading across orthographies. How fast and how well children learn to read depends partially on the characteristics of the orthography. Phonological decoding is important for reading in all orthographies, but to different degrees, depending on the mapping system that is used in a particular orthography. What do these similarities and differences mean in terms of how the brain reads different orthographies?
Is There a Universal Brain Network for Reading Across Orthographies?
Even though there are differences in how quickly children learn to read and in the reading problems children have in different orthographies, there is reason to believe that reading in all languages uses some of the same areas of the brain. The first step when reading in any language is looking at and analyzing the printed word. Also, all orthographies represent spoken language, which suggests that phonological decoding, or figuring out which sounds the symbols represent, is required for all reading. Brain imaging studies, in which special equipment is used to take “pictures” of the brain, can tell us a lot about how the brain reads different orthographies. The most common brain imaging techniques used to explore the reading of languages are called functional magnetic resonance imaging (fMRI) and positron emission tomography (PET) scans. Both fMRI and PET scans create pictures of the brain when it is working on a task, enabling researchers to see which areas of the brain are being used when you are reading. Using these tools to compare brain activity when a person is reading different orthographies, researchers can identify brain regions that are used when reading all orthographies, and brain regions that are used only when reading specific orthographies.
One group of researchers identified three areas in the left hemisphere (or side) of the brain that are used when reading in all orthographies studied [5]. These researchers combined the results of 43 different fMRI and PET studies of reading in several different languages, including English, French, Italian, German, Danish, Chinese, Japanese Kana, and Japanese Kanji. The three brain regions used in all orthographies were a region at the top of the left temporal lobe toward the back of the brain called the temporal–parietal area, which may be involved in phonological decoding, a region along the bottom of the left frontal lobe called the inferior frontal gyrus, and the visual word form area (VWFA). The VWFA is a region of the fusiform gyrus, which is located along the bottom of the temporal and occipital lobes in the left hemisphere of the cerebral cortex (see Figure 2). The VWFA is believed to be used only when we see written letters and words, and not when we see other objects, and the VWFA has been found to be involved in reading in all orthographies studied so far [6].
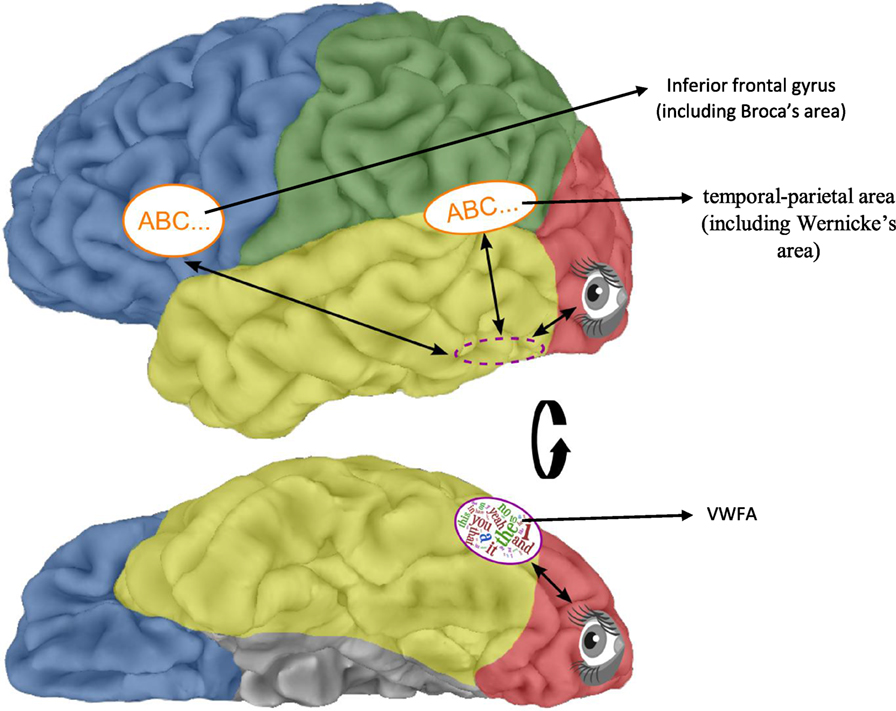
- Figure 2 - Brain regions used when reading in all orthographies.
- The upper figure illustrates the left hemisphere (side) of the brain, viewed from the side. The occipital lobe (red), involved in visual processing, and two language areas, one (Broca’s area) in the inferior frontal gyrus of the frontal lobe of the brain (blue), and the other (Wernicke’s area) at the intersection of the temporal (yellow) and parietal (green) lobes are all involved in reading across all languages. The visual word form area (VWFA) is the region of the brain that is devoted exclusively to reading. We can see the VWFA (purple oval with words), in the lower figure, which shows a bottom view (looking up) of the left hemisphere of the brain. In the top figure, the dashed purple oval indicates where the VWFA would be if we could see it from the side view. Image from Kassuba and Kastner [7]. Copyright© 2015 Kassuba and Kastner.
The same group of researchers also identified several areas of the brain that are used only when a specific orthography was being read. For example, the fusiform gyrus in the right hemisphere (side) of the brain was active when reading Chinese, but not the other languages. This pattern of brain activity means that, when reading Chinese, the fusiform gyrus in both the left and right hemispheres is used, but when reading any of the alphabetic orthographies, only the left hemisphere fusiform area, the VWFA, is used. Researchers think that the brain regions used only when reading Chinese may be used to help make connections between the meaning and the sounds of a word and in reading the squared-shaped layout of Chinese characters.
Reading is a complex task, and a relatively new skill for the human species. It is likely that some regions of the brain have, over time, become adapted for, or better at, the task of reading. Research shows that there are some common brain areas involved in reading across all languages, areas that are involved in visual recognition of the symbols and figuring out which sounds the symbols represent. However, specialized areas of the brain also exist, which support the particular skills needed to read a specific orthography. Most research studies to date have focused on alphabetic orthographies, and mostly orthographies that are based on the Latin alphabet. Further research is needed to explore reading in other orthographies if we are to know for sure whether the brain reads all languages the same way.
Glossary
Orthography: ↑ The symbols used to represent a spoken language.
Morpheme: ↑ Root words or parts of words that can be added or removed from a word to change its meaning. For example, in English, a morpheme can be a word (e.g., build), a prefix (e.g., the “re” in the word “rebuild”), a suffix (e.g., the “er” in the word “builder”), or a grammatical inflection (e.g., “s” for plural in the word “builders”).
Phonological decoding: ↑ Converting written symbols into the sounds they represent.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
[1] ↑ Comrie, B., ed. 2009. The World’s Major Languages.
[2] ↑ Seymour, P. H. K., Aro, M., and Erskine, J. M. 2003. Foundation literacy acquisition in European orthographies. Br. J. Psychol. 94:143–74. doi:10.1348/000712603321661859
[3] ↑ Brunswick, N. 2010. Unimpaired reading development and dyslexia across different languages. In: Reading and Dyslexia in Different Orthographies, eds. N. Brunswick, S. McDougall, and P. de Mornay Davies, 131–54. New York, NY: Psychology Press.
[4] ↑ Perfetti, C., Cao, F., and Booth, J. 2013. Specialization and universals in the development of reading skill: how Chinese research informs a universal science of reading. Sci. Stud. Read. 17:5–21. doi:10.1080/10888438.2012.689786
[5] ↑ Bolger, D. J., Perfetti, C. A., and Schneider, W. 2005. Cross-cultural effect on the brain revisited: universal structures plus writing system variation. Hum. Brain Mapp. 25:92–104. doi:10.1002/hbm.20124
[6] ↑ Carreiras, M., Armstrong, B. C., Perea, M., and Frost, R. 2014. The what, when, where, and how of visual word recognition. Trends Cogn. Neurosci. 18:90–8. doi:10.1016/j.tics.2013.11.005
[7] ↑ Kassuba, T., and Kastner, S. 2015. The reading brain. Front. Young Minds. 3:5. doi:10.3389/frym.2015.00005