
摘要
这个世界上有至少六千多种语言,而语言的书写形式我们称它为正字法。正字法就是那些我们用来表示口语的标志与符号。你现在眼前的字就是一种正字法!总之,正字法由一系列符号组成,把口语 ''编码'' 成书面形式。但是,不同正字法中每个符号所代表的读音单元不同。在使用字母的正字法中,例如英语、西班牙语、俄语的书写,每个字母都代表一个独立的发音,叫做音素 (比如英文单词 book 中的发音/b/就是一个音素)。而在非拼音文字的正字法中,比如中文和切诺基语,每个符号所代表的读音比音素大,是一个音节。今天,我们所知的正字法有四百多种,分为拼音文字正字法,比如英文,和非拼音文字正字法,比如中文。在这篇文章里,我们会首先学习不同正字法的特点,然后再来了解不同的书写体系会如何影响阅读的过程。最后,我们来看看大脑的哪些区域和阅读有关。
我们首先来看看拼音文字的正字法。这类文字在书写时使用字母。比如英文使用拉丁字母,并用二十六个字母来书写,挪威语和斯洛伐克语也用了同样的拉丁字母,但挪威语比英文多了三种元音 (å,æ, ø), 而斯洛伐克语在字母上加了重音符号(例如 ó 或 š) 来表示字母的发音,所以有四十六个字母。大多欧洲的语言,包括英语、法语、西班牙语、意大利语、荷兰语、挪威语、德语、葡萄牙语、捷克语、斯洛伐克语、匈牙利语、波兰语、丹麦语、威尔士语、瑞典语、冰岛语、芬兰语、和土耳其语都使用拉丁字母 [1]。
世上也有其他不同的字母体系,但都是以 ''音素'' 为单位进行编码的。例如俄语、保加利亚语、和乌克兰语使用的西里尔字母,作为印度官方语言之一的印地语所使用的梵文字母,仅在希腊文中使用的希腊字母,和韩文使用的韩语字母。而有些语言,比如塞尔维亚克罗地亚语,会结合拉丁和西里尔字母,使用不只一种字母体系。一个以音素为单位的正字法,如果只有辅音且没有元音,便称为辅音音素文字。希伯来文和阿拉伯文经常被称为辅音音素文字,因为它们书写的传统是不写元音的,但如今人们会用重音符号来标志元音的位置,因此许多人认为这两种语言应该被归类为普通的音素文字。在图 1 中你可以对比用几种不同正字法写出的 ''我认为我可以'' 。
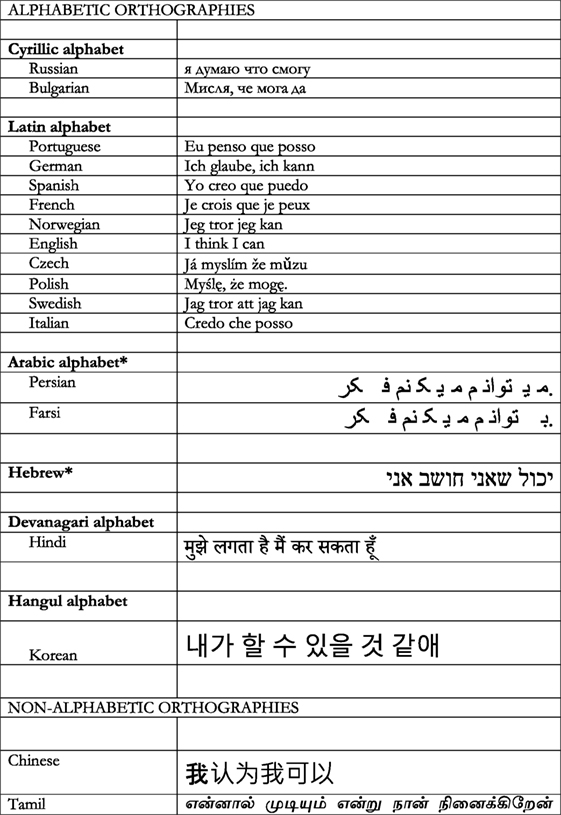
- 图 1 - 使用不同正字法写出的 ''我觉得我可以。''
- 标 * 的语言需要从右到左读。
不同正字法的音素(发音)和字素(符号或字母)如何匹配也有差异。有些语言,比如西班牙语、意大利语和德语几乎每个字母只会有一个发音,那么我们可以说这套字母的映射是很 ''一致'' 的,而正字法的深度是 ''浅层'' 的。而其他语言,比如在英语和丹麦语中,一个字母可以有许多发音,比如在单词 ''circus'' 中,两个字母 c 的发音不一样,那么我们说字母的映射 ''不一致'' ,这套正字法是 ''深层'' 的。虽然科学家们对于如何比较不同语言的正字法深度观点不一致,但是大多数学者认为芬兰语、希腊语、意大利语、西班牙语、德语、塞尔维亚克罗地亚语、土耳其语、和韩语是相对 ''一致'' 并且 ''浅层'' 的正字法,而葡萄牙语、法语和丹麦文使用比较有 ''深度'' 的正字法。英文是世界上最 ''不一致'' 的语言呢!
接下来,我们来看看非拼音文字正字法。这些正字法的符号通常代表一个音节(切诺基语、泰米尔语,或日文的片假名),或是以意义为单位(中文、日文的汉字)。与拼音文字的正字法类似,不用拼音的正字法也会使用符号,只是每个符号所代表的口语发音比一个音素大。中文常被描述为象形文字,因为人们觉得汉字像是在用一幅幅图画表达意思。但其实大部分的汉字都不是象形字,而是表达了语素和音节的符号,因此中文被称为语素音节文字。另外,大约八成到九成的汉字都含有 ''声旁'' ,来表示字的读音。图 1 中能看得到中文与泰米尔语的举例。
因此,所有的正字法都有共同点但也各有不同。它们都使用书面符号来代表口语。但从口语转换成书写时,如何对口语进行编码,不同的语言之间会有差别。接下来我们来探讨这些差别如何影响阅读过程,人类的大脑是怎样阅读不同语言的。
读某些语言会比其他语言困难吗?
小孩子在学习阅读时,他们学得有多快、多好其实和语言种类有关。因为不同语言的正字法有不同的特点 [2]。有一个大型研究,对比了孩子们认读 14 种拼音文字的情况。结果发现,在小学一年级结束时,学习阅读浅层正字法的学生(西班牙语、芬兰语、希腊语),比学习深层正字法的学生(丹麦语、英语)读得更快,错误更少 [2]。尽管不同国家教育方式不同,这会造成一些影响,但毋庸置疑,书面和口语 ''一致'' 的语言比 ''不一致'' 的语言更容易学习。事实上,学读英文比学读几乎其它所有拼音文字都更费时间,而认读中文则要花费更久 [3]。
孩子们在学习不同的正字法时会遇到不同的困难吗?
有些孩子在学习认读时有巨大困难,这有可能是由于发展性阅读障碍。有这个障碍的孩子无法具有与同龄人相同的阅读能力。这不是由教学质量、视力、听力、或其他脑部疾病导致的。据统计,大约百分之五的孩子都有严重的阅读障碍。
不论在哪种语言环境下,有阅读障碍的孩子都对于把符号转换成声音感到困难 [3]。这个转换的技能叫做语音解码。对于不同的语言,语音解码的困难程度不一样。在浅层正字法语言中,比如德语、西班牙语、意大利语,有阅读障碍的孩子可以正确地读出文字,但速度比较慢。而在深层正字法语言中,阅读障碍会产生很大影响。在英语环境下,有阅读障碍的孩子会读错很多文字 [3]。同样,在读汉语,这个非拼音语言时,有阅读障碍的孩子也会感到很难。他们无法解读出声旁所代表的发音,因此阅读对他们来说得困难。但这其实并不是最主要的原因。阅读汉语时,语素意识,也就是理解汉字代表的意思的技能,更加重要。而有阅读障碍的孩子因为这个能力出了问题,所以在阅读中文时会有困难 [4]。因此,对于讲汉语的人来说,语音解码很重要,但没有在拼音文字中重要 [3]。而在阅读拼音文字时,语音解码对于深层正字法(如英语)比对浅层正字法(如西班牙语)影响大。
以上我们探讨了阅读各种正字法的相同与不同之处。孩子在学习认读时学得有多快、多好,有一部分取决于正字法的特点。语音解码这个技能虽然在每个正字法中都很重要,但重要程度有差别,这与正字法深度有关。那么这与人的大脑怎样阅读不同的正字法有联系吗?
大脑是如何阅读的?读不同正字法的过程相同吗?
无论阅读哪种语言,大脑中激活的区域都是相同的。阅读任何语言的第一步,都是要看并且分析纸上的字。同时,所有正字法都是用来代表口语的,因此无论哪种语言,阅读时大脑都需要进行语音解码,弄清哪个符号代表哪种发音。我们使用特殊仪器拍摄大脑内部活动,来了解大脑是如何阅读不同正字法的。最常使用的技术叫做 ''功能磁共振成像 (fMRI)'' ,以及正电子发射断层扫描(PET)。这两种技术都可以拍摄到大脑在完成某项任务时所使用到的区域。这样研究人员便可以对比,找出有哪些区域是阅读所有正字法时都会用到的,而哪些是只有阅读某些正字法时才会用到的。
有一些科研人员找到了左脑中的三个区域,在阅读所有文字时都会用到 [5]。他们对比了 43 个 fMRI 和 PET 扫描结果,研究了大脑在阅读英语、法语、意大利语、德语、丹麦语、中文、日文汉字时的活动区域。发现这三个区域中,第一个位于脑袋后部,左颞叶的上方,称为颞顶区,参与了语音解码。第二个位于左前叶的底部称为下额回的地方,而第三个称为视觉词形区 (VWFA)。视觉词形区是梭状回的一部分,位于大脑皮层左半边颞叶跟枕叶的底部(如图 2)。视觉词形区只会在读字的时候用到,而在看其他物体时并不会使用。根据目前为止的研究,阅读所有正字法时这个区域都会被用到 [6]。
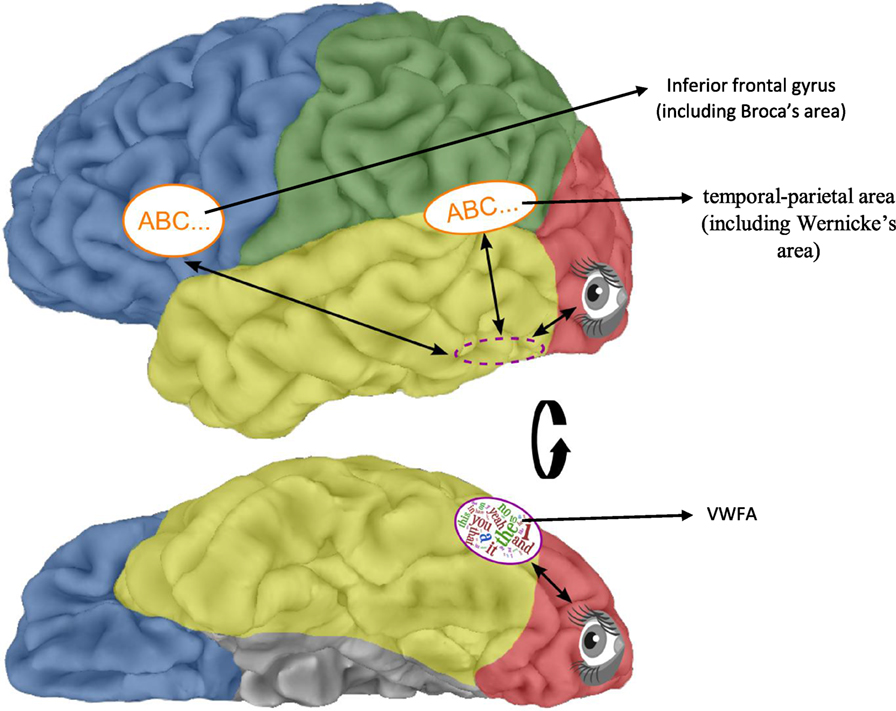
- 图 2 - 阅读任何正字法都会用到的大脑区域。
- 上方的图中画出了大脑左半边的侧面图。枕叶(红色)的作用是视觉处理,而两个语言区,一个(布洛卡区)在额叶的下额回里(蓝色),而另一个(威尼克区)则在颞叶(黄色)和顶叶(绿色)的交叉处,两个区域都在阅读任何正字法时使用用到。视觉词形区域是只有阅读时才会用到的区域,而这个区域(紫色椭圆)可以在下方的左脑底部视图中看到。上方图中的紫色虚线画的椭圆形代表视觉词形区的位置,但因为是侧面图所以看不到。 图片来自 Kassuba 和 Kastner [7]。 Copyright© 2015 Kassuba and Kastner。
这些科研人员也找到了一些只会在阅读某些正字法时使用到的区域。例如,右脑的梭状回只有在阅读中文时会被激活。这代表阅读中文时,大脑两侧的梭状回都会用到,但是读拼音类文字正字法时只会用到左半边的,也就是视觉词形区。科研人员认为这个只有在读中文时会用到的区域,能够将字的意思、发音和汉字的样子关联起来。
阅读是复杂的过程,也是对于人类来说比较新的技能。也许是经历了岁月,大脑的某些区域变得更加擅长阅读了。研究发现有些大脑区域在阅读任何语言时都用到了,比如参与识别符号的区域,和弄清符号所代表的发音的区域。也有一些特别的区域,只在阅读特定的正字法时才会被激活。迄今为止大多的研究都专注于拼音文字正字法,尤其是基于拉丁字母的文字。要想更多了解大脑是如何阅读不同语言的,我们还需要更多学习大脑是如何阅读其他正字法的。
词汇表
正字法 (Orthography): ↑ 用来代表口语的书写符号。
词素 (Morpheme): ↑ 词根或是一个词的一部分,如果移除或加上可以改变整个词的意思。
语音解码 (Phonological Decoding): ↑ 把书写符号转换为发音。
利益冲突声明
作者声明, 该研究是在没有任何可能被解释为潜在利益冲突的商业或财务关系的情况下进行的。
参考文献
[1] ↑ Comrie, B., ed. 2009. The World’s Major Languages. 2nd ed. New York, NY: Routledge.
[2] ↑ Seymour, P. H. K., Aro, M., and Erskine, J. M. 2003. Foundation literacy acquisition in European orthographies. Br. J. Psychol. 94:143–74. doi: 10.1348/000712603321661859
[3] ↑ Brunswick, N. 2010. Unimpaired reading development and dyslexia across different languages. In: Reading and Dyslexia in Different Orthographies, eds. N. Brunswick, S. McDougall, and P. de Mornay Davies, 131–54. New York, NY: Psychology Press.
[4] ↑ Perfetti, C., Cao, F., and Booth, J. 2013. Specialization and universals in the development of reading skill: how Chinese research informs a universal science of reading. Sci. Stud. Read. 17:5–21. doi: 10.1080/10888438.2012.689786
[5] ↑ Bolger, D. J., Perfetti, C. A., and Schneider, W. 2005. Cross-cultural effect on the brain revisited: universal structures plus writing system variation. Hum. Brain Mapp. 25:92–104. doi: 10.1002/hbm.20124
[6] ↑ Carreiras, M., Armstrong, B. C., Perea, M., and Frost, R. 2014. The what, when, where, and how of visual word recognition. Trends Cogn. Neurosci. 18:90–8. doi: 10.1016/j.tics.2013.11.005
[7] ↑ Kassuba, T., and Kastner, S. 2015. The reading brain. Front. Young Minds. 3:5. doi: 10.3389/frym.2015.00005