
Abstract
Imagine you are a police officer investigating a crime in which somebody has made a threatening phone call. There may not be any physical evidence like DNA or fingerprints, but the person’s voice is captured on a recording. Experts can analyze the voice recording and compare it with the voice of a known suspect to find out how likely it is that they are the same person. This method is called forensic voice comparison. It works because people’s voices contain lots of information about them. Your voice tells a story about where you grew up and learned to speak, and your voice also depends on your individual biological make-up. In this article, we explain how this information is used to compare recordings of voices in criminal cases.
How Your Voice Works
Imagine that a criminal has made a threatening phone call, and the police have a recording of the call but do not know who made it. The voice in the recording can be compared to the voices of suspects, to try to identify the criminal. This process is called forensic voice comparison [1].
To understand forensic voice comparison, we need to understand how sound and voices work. All sound is made up of vibrations in the air, and the frequency of a sound is how fast it makes the air vibrate. We hear low frequencies as low pitches and high frequencies as high pitches, but most natural sounds contain lots of frequencies that give us additional information—for example, a violin and a piano playing the same note sound different because they contain other frequencies as well as the pitch.
When we speak, sound is produced by the vocal cords, which are two small, vibrating muscles in your throat. The vocal cords make a buzzing sound, and how fast they vibrate determines the pitch of your voice. To turn the buzzing sound into speech, you also need the vocal tract, which is the name for the flexible tube between your vocal cords and your lips. To make specific speech sounds, you change the shape of this tube by moving what are called your articulators: your tongue, jaw, and other parts of your mouth. This changes the frequencies that are present in your voice [2].
Try it now: start by humming and place your hand on your throat. You should feel a vibration, caused by your vocal cords. While you are humming, your mouth is closed—your articulators are in the position used to produce the sound “m.” Now, while still humming at the same pitch, open your mouth. It will sound like “ma” as your articulators move from the position for “m” to the position for “ah.” You did not change the pitch of your voice, but by changing the shape of the vocal tract, you changed the other frequencies that were present, resulting in different speech sounds.
People’s voices are different from each other for two reasons: biological differences in the size and shape of their vocal cords and vocal tracts, and behavioral differences in how they have learned to use their voices. For example, larger people will have bigger vocal cords, giving them lower-pitched voices. They did not learn this, it is just a result of their size. Alternatively, people with different accents might pronounce words differently. An English person might say “down” or “daan,” but a Scottish person might pronounce it “doon.” These people have learned to move their articulators differently, based on where they learned to speak.
The same person’s voice can also be different in different situations. You probably know how different someone’s voice sounds when they have a cold. This is because the nose is blocked, changing how air flows around the vocal tract. There are lots of reasons that your voice might change, including who you are speaking to, your mood, and even the time of day. Even if someone said the same thing one hundred times, no two repetitions would be identical. It is important to know about these differences when we compare voices from various situations.
Comparing Voices
Due to the biological and behavioral differences in how people speak, voices contain information that is specific to each person. This allows people to be recognized from their voices.
To compare two voices and judge whether they belong to the same person, we need to consider how similar the voices are. If they are not very similar, this might suggest that the suspect is not the criminal. We also need to consider how distinctive the voice is. Two people may have similar voices just because they grew up in similar places. Therefore, forensic analysts explore whether the voices contain distinctive features that would not be shared by many people from a similar background. Voices that share a greater number of distinctive features provide stronger evidence that the suspect and the criminal are the same person, because fewer other people’s voices would share those features.
It is difficult to say with 100% certainty that a voice in a recording belongs to a suspect because the human voice is so complex. Whereas, our DNA or fingerprints remain fixed throughout our lives, voices change for all sorts of reasons. This means that the same person could sound very different in two recordings made in different situations. In our example, the recording of the criminal’s voice could be compared with a suspect’s police interview recording. The situation of making a threatening telephone call is very different from the situation of being interviewed by the police, so a person’s voice is likely to differ between these two settings. It is also possible that a person will change their voice when committing a crime, to disguise their own voice or sound like somebody else. This may make it very difficult to compare voices, but sometimes features can be detected despite the disguise.
Linguistic Analysis
Voices are analyzed by experts trained in linguistics, which is the scientific study of language and speech. Linguists examine various linguistic features in the threatening call and compare them with similar features in the police interview [3]. They break the speech down into various parts and analyze each part by carefully listening to specific sounds. This is called auditory analysis. They also examine speech using computer software to look at images of speech sounds, called spectrograms, such as those in Figure 1. This process is called acoustic analysis.
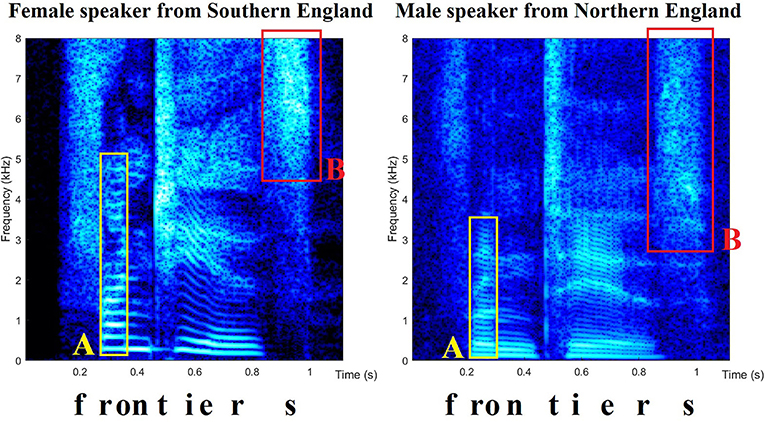
- Figure 1
- Spectrograms of two speakers saying “frontiers.” The brighter the image, the more sound energy there is at that frequency and time. There are lots of differences between the speakers: for example, boxes A and B contain the sounds “ro” and “s” but look very different for each speaker. The bright horizontal lines occur whenever the sound has a pitch and are more widely spaced for higher-pitched voices. Noisy sounds like “s” appear as wide frequency bands instead of lines and do not have a pitch (try singing “s” and you will find it does not sound different at high or low notes).
Linguistic features that are commonly analyzed include:
Voice quality: The overall sound of someone’s voice. Some people’s voices sound rough or harsh, some sound creaky or croaky, and some sound like they have a cold. Voice quality is assessed and compared across a range of categories like this.
Pitch: How high- or low-pitched a voice sounds. Pitch changes due to differences in the shape and size of the vocal cords, but also from the way speakers use their vocal cords, for example to express emotion when they speak.
Vowel and consonant sounds: The pronunciation of specific vowels and consonants can be analyzed to show the speaker’s behavior, which might help to define the accent a speaker has. There may also be additional unusual features, like a lisp, or producing “r” to sound like “w.”
Timing and rhythm: How slow or fast a person speaks, and how they place stress on different syllables and words.
Level of fluency: When speakers pause, hesitate, interrupt, or repeat themselves, these are called disfluencies. Some speakers use lots of disfluencies and others use very few; they may also use distinct types of disfluencies.
Wording and grammar: Speakers might repeatedly use distinctive words or phrases, or they might use unusual sentences in a similar way.
Some linguistic features will be related to the speaker’s accent, and some will be more individual. By analyzing a range of features, a full “profile” of each speaker’s voice can be generated and compared with other profiles. The forensic analyst can then produce a conclusion regarding how strong the evidence is that the criminal and the suspect are the same person.
Automated Computer Analysis
Computers can also be used to compare voices automatically, using a process called automatic speaker recognition (ASR). This is similar to technology used by banks, in which you can use your voice as a password. Rather than analyzing the linguistic aspects of speech, the computer analyzes the voice recording as a whole, identifying the biological as well as behavioral characteristics of a speaker. The computer software makes thousands or millions of measurements from each voice recording and uses complicated statistical models to turn these measurements into a speaker profile. The software also analyzes the profiles of hundreds of other speakers so it can determine whether the profiles are distinctive or not. So, in our case, a sample of speech from a threatening phone call would be analyzed and compared with the police interview. This type of analysis can be used on its own but, in most cases, it is used alongside linguistic experts [4]. One of the benefits of using a computer is that it can analyze hundreds or even thousands of samples, because it works much faster than a human could.
Conclusion
There are lots of differences between people’s voices, and some differences are biological while others are behavioral. By comparing many voice characteristics, especially those that are known to vary a lot between individuals, experts can decide how likely it is that two voice recordings come from the same person. This type of voice comparison evidence can be provided for the police or for a court. This evidence might help law enforcement decide whether they have the right suspect, or used in a trial to help decide if a person is guilty of a crime. Now that almost everyone has a smartphone that can easily record audio and video, voice evidence is becoming more common and can be critical in solving crimes.
Glossary
Forensic Voice Comparison: ↑ The use of scientific techniques to determine how likely it is that speech samples came from the same person, to help in criminal investigations, and other legal matters.
Frequency: ↑ The number of vibrations per second in a sound wave. High notes have a high frequency and low notes have a low frequency.
Linguistics: ↑ The scientific study of how languages are formed, used, and understood.
Auditory Analysis: ↑ A form of forensic speech analysis performed by experts, involving careful listening to different parts of voice recordings.
Spectrogram: ↑ A visual representation of a sound signal, such as speech, which shows the frequencies that are present and how they change over time.
Acoustic Analysis: ↑ A form of forensic speech analysis performed by experts, making use of spectrograms, and other quantifiable measurements to determine the specific frequencies present in different parts of voice recordings.
Disfluencies: ↑ Speech habits that interrupt the regular flow of speech, such as pauses, stutters, hesitations, and using filler words like “um” and “er.”
Automatic Speaker Recognition (ASR): ↑ A form of speech analysis performed by computers and based on a large database of voices, to determine how similar, and distinctive two voice recordings are.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
AG was currently supported by a British Academy Postdoctoral Fellowship, PF19/100024. VH, PH, and AG were previously supported by the AHRC award Voice and Identity: source, filter, biometric, AH/M003396/1.
References
[1] ↑ Jessen, M. 2008. Forensic phonetics. Lang. Linguist. Compass. 2:671–711. doi: 10.1111/j.1749-818X.2008.00066.x
[2] ↑ Lieberman, P., and Blumstein, S. E. 1988. Speech Physiology, Speech Perception, and Acoustic Phonetics. Cambridge: Cambridge University Press.
[3] ↑ Foulkes, P., and French, P. 2012. “Forensic speaker comparison: a linguistic–acoustic perspective,” in The Oxford Handbook of Language and Law, eds L. M. Solan, and P. M. Tiersma (Oxford: Oxford University Press). p. 418–21.
[4] ↑ Parliamentary Office of Science and Technology. 2015. Forensic Language Analysis: POSTnote. Parliamentary Office of Science and Technology. Available online at: https://post.parliament.uk/research-briefings/post-pn-0509/